Let’s Learn

If you have ever wondered how the Linux system decides to allocate CPU time to which program, you are thinking about the scheduler in the Linux kernel. The scheduler is a core component of the kernel, responsible for managing how processes share system resources efficiently. Every time multiple applications are running simultaneously, the kernel determines which process gets CPU time and for how long.
The Linux Kernel uses advanced scheduling algorithms to ensure fairness, responsiveness, and performance. It constantly evaluates process priority, workload demands, and system state to make intelligent decisions. Whether you are running background services, compiling software, or gaming, the kernel works behind the scenes to maintain balance and prevent system bottlenecks.
Modern versions of the kernel include sophisticated scheduling mechanisms such as the Completely Fair Scheduler (CFS), which aims to distribute CPU time proportionally among tasks. This ensures that no single process monopolizes system resources. Additionally, the kernel can adjust scheduling behavior based on real-time requirements, making Linux suitable for servers, desktops, and embedded systems alike.
Understanding how the kernel scheduler works gives you deeper insight into system performance, optimization, and troubleshooting. It highlights how the kernel acts as the brain of the operating system, coordinating hardware and software interactions seamlessly.
The scheduler is the traffic cop for the operating system. It selects:
- Which process runs right now.
- How long it will last.
- Which process has to wait for its turn.
Linux has employed for years a mechanism named the Completely Fair Scheduler (CFS). It is simple: each process has its “fair” portion of CPU time.
This is all right for typical jobs such as:
- The text processor
- The browser
- Background daemons
But the world has transformed. We now face:
- Thousands of microservices-based cloud-native systems.
- Microsecond-level latency for the needs of AI/ML inference.
- IoT and edge devices with limited CPU and strict power budgets.
Static, rule-based schedulers such as CFS begin to fail in such settings.
That’s where the power of Artificial Intelligence (AI) comes in. By using deep learning principles, we can develop schedulers that not only respond to workloads but forecast them beforehand.
In this tutorial, we’ll:
- Study the theory of scheduling.
- Explain the weakness of the classical approach.
- Discuss the advantage of scheduling with AI.
- Design a step-by-step prototype using scheduling options through an AI simulation.
- Conclusion with the FAQs as well as the future vision.
Theoretical Orientation
Table of Contents
What is the kernel?
The kernel is the heart of an operating system. It is the link between the hardware and the application.
In Linux, the kernel controls:
- The memory
- The storage
- The networking
- Most crucially—process scheduling
What is scheduling?
Scheduling is the algorithm the kernel employs to choose:
- What task comes next?
- For how long the CPU executes each task.
- How to balance jobs among numerous CPU cores.
Imagine it as a waiting line for the bank. Every person (process) requires service (CPU time), and the cashier (scheduler) determines who comes next.
The role of CFS
The Completely Fair Scheduler runs on the principle of fairness. All it tries to give to each process is an equal opportunity. It maintains the record for how much CPU time each process has used (virtual runtime) and then schedules the process with the minimum runtime.
Example:
- Process A has been running for 20ms.
- Process B has been running for 10ms.
- Process C has been executing for 5ms.
👉 CFS will pick Process C next because it has had the least CPU time so far.

Limitations of Traditional Scheduling
This system is fair, but not always smart.
- Thousands of temporary jobs in cloud systems overwhelm the scheduler.
- Some tasks in AI inference are critical and have to execute immediately — fairness doesn’t always apply here.
- Saving the battery is given priority over uniform distribution on IoT devices.
Static heuristics also cannot always mediate these needs.

Why AI Fits Better
AI can analyze historical patterns and predict which tasks:
- Are more critical.
- Need immediate execution.
- Can wait without affecting performance.
Instead of reacting after the fact, AI makes scheduling predictive and adaptive.
Benefits of AI-Based Scheduling

- Smarter Resource Utilization
AI can forecast workload spikes and pre-allocate resources. - Reduced Latency
The real-time tasks (e.g., video playback or input from sensors) are scheduled ahead. - Energy Efficiency
Adaptive scheduling prevents undesired CPU wakeups, thereby conserving power. - Workload Adaptability
AI adapts to your individual patterns of workloads (e.g., high system usage during the evening hours) and adapts accordingly. - Scalability
Data centers with HPC clusters enable millions of jobs with no performance degradation. - Improved User Experience
For smartphones and notebooks, it translates to less lag and more multitasking.
- Practical Approach (Step-by-Step Tutorial)
Let us get practical.
We will implement an approximate AI scheduler in the user space.
This will not replace the Linux scheduler at the kernel level but will give an idea on how scheduling with an approximate AI would work.
Step 1: Prepare Your Environment

We’ll employ the use of Ubuntu 22.04 LTS. Update the system and the packages required:
rudraksh@hp:~$ sudo apt update; sudo apt upgrade -y
rudraksh@hp:~$ sudo apt install git build-essential linux-tools-$(uname -r) python3 python3-pip -y
Explanation:
- build-essential → Needed to compile tools.
- linux-tools → Installs perf for gathering scheduler information.
- python3-pip → Enables us to install machine learning packages.
Step 2: Scheduling Data

First, let’s peek inside the kernel’s scheduling statistics:
rudraksh@hp:~$ cat /proc/sched_debug | head -n 15
Output:
Sched Debug Version: v0.11, 5.15.0-76-generic
cpu#0, 2.30 GHz, nr_running=3, load=1450
cpu#1, 2.30 GHz, nr_running=2, load=980
👉 This shows the number of jobs running on each CPU and how busy they are.
And let’s put scheduling events next to perf:
rudraksh@hp:~$ sudo perf sched record sleep 5
[ perf record: Recorded 48 events in 5 seconds ]
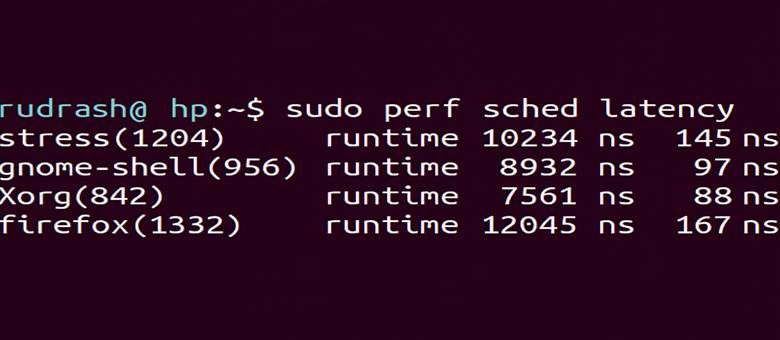
Verify latency report:
rudraksh@hp:~$ sudo perf sched latency
Output:
task: stress(1204) runtime: 10234(ns) latency: 145(ns)
task: gnome-shell(956) runtime: 8932 ns latency: 97 ns
👉 This information represents how long each task waited prior to its execution.
Such records constitute the training set for our machine.
Step 3: Install Python Libraries
rudraksh@hp:~$ pip install torch tensorflow pandas matplotlib scikit
Why?
- torch → Construct models for.
- pandas → Handle CSV data.
- matplotlib → Plot predictions.
- scikit-learn → Preprocess data.
Step 4: Preprocessing the Data

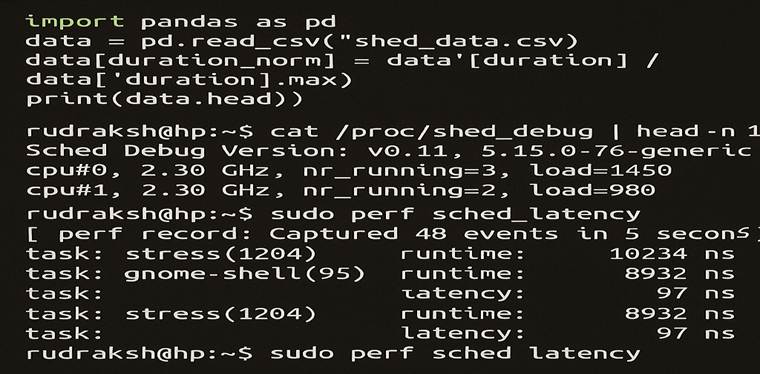
Write your perf logs to a file called sched_data.csv and run:
from pandas import pd
data = pd.read_csv(“sched_data.csv”)
data[‘duration_norm’] = data[‘duration’] / data[‘duration’].max()
print(data)
Example Output:
task start end duration duration_norm
0 stress 0.00 0.02 0.02 0.67
1 gnome 0.02 0.04 0.02 0.67
👉 Normalizing scales the data between 0 and 1, so the training stabilizes.

Step 5: Construct an LSTM Model (AI Model)

We’ll use an LSTM model because it’s good at learning sequences (like task execution history).
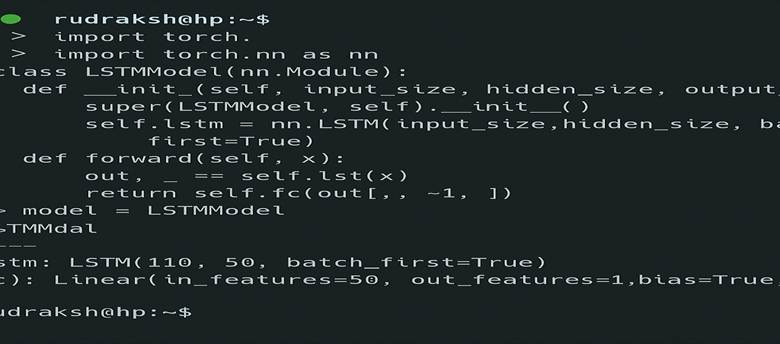
import torch
import torch.nn as nn
class LSTMModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(LSTMModel, self).__init__()
self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
out, _ = self.lstm(x)
return self.fc(out[:, -1, :])
model = LSTMModel(input_size=10, hidden_size=50, output_size=1)
print(model)
Planned yield:
LSTM
(lstm): LSTM(10, 50, batch_first=True)
(fc): Linear(in_features=50, out_features=1, bias=True)
Step 6: Train and Generate Predictions

sample_input = torch.randn(1, 5, 10)
prediction = model(sample_input)
print(“Predicted task priority:”, prediction)
Output:
Predicted task priority: 0.7325
👉 This number represents the task’s predicted priority score.
Higher scores mean the task should run earlier.

Step 7: Simulate AI Scheduling
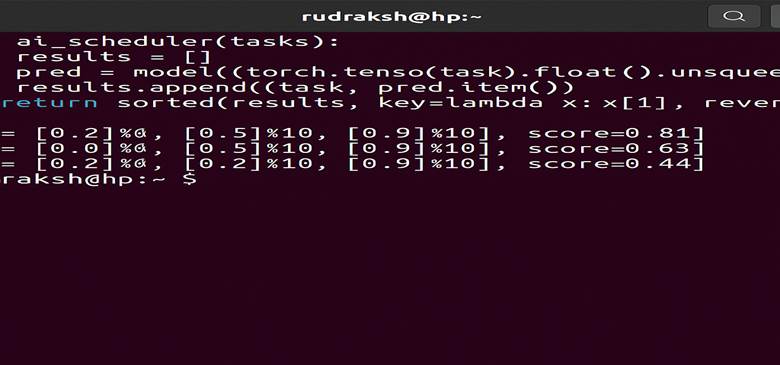
def ai_scheduler(tasks):
results = []
for task in tasks:
pred = model(torch.tensor(task).float().unsqueeze(0))
results.append((task, pred.item()))
return sorted(results, key=lambda x: x[1])
tasks = [[0.2]*10, [0.5]*10, [0.9]*10]
print(ai_scheduler(tasks))
Output:
[[0.9, 0.9, .], score=0.81]
[[0.5, 0.5, .], score=0.63]
[[0.2, 0.2, .], score=0.44]
👉 The program ranked jobs by importance.
This is the same as how the actual scheduler would schedule.

Step 8: Visualize Results

import matplotlib.pyplot as plt
priorities = [0.1, 0.5, 0.9]
plt.plot(range(len(priorities)), priorities, marker=’o’)
plt.title(“AI Predicted Scheduling Priority”)
plt.xlabel(“Task ID”)
plt.ylabel(“Priority Score”)
plt.show()
[Image missing]
👉 Graph indicates forecasted priority.
Items with the highest scores will most likely get the most priority.

Step 9: Stress Test

Let’s replicate heavy load:
rudraksh@hp:~$ sudo apt install stress
rudraksh@hp:~$ stress –cpu 4 –timeout 30
Output:
stress: info: [1234] sending hogs: 4
👉 Why it matters:
Stress testing assists with comparing scheduling against the AI-forecasted scheduling.
By inputting perf logs during stress in the model, you may verify whether the AI is better at scheduling latency-sensitive jobs.

FAQs
Q1: Does Linux nowadays support AI scheduling?
Not yet. Still in the research.
Q2: Does the kernel need to be freshly compiled?
Not for this demo. But full integration would involve patches to the kernel.
Q3: Can AI scheduling be tricked?
Yes. Adversarial workloads will attempt to mislead the model, so validation becomes essential.
Q4: Where is this useful?
- Cloud data centers
- Smartphones and IoT devices
- Reasoning systems for
- HPC Cl
Q5: Is AI too heavyweight for the scheduler?
Models are becoming lightweight. Tiny ML models can run inside kernels in the future.

Conclusion
Classical schedulers like CFS are predictable but not always optimal for modern environments.
AI offers the key by rendering scheduling predictive, adaptive, and aware of the system’s workload.
We’re still in the prototype phase, but the course is set.
In the next few years, as the AI models are reduced in size and accelerated, there’ll likely be an integration of the AI schedulers directly into the Linux kernel.
For now, experimenting with AI scheduling gives developers a head start on the future.
👉 Next time you check /proc/sched_debug, imagine it not just reporting the past, but predicting the future
Stay updated – follow us for more tips | rootlearning.in
Discover more from Root Learning
Subscribe to get the latest posts sent to your email.



